Phantom-GRAPE: Numerical Software Library to Accelerate Collisionless N-body Simulation with SIMD Instruction Set on x86 Architecture by Tanikawa, Yoshikawa, Nitadori & Okamoto
AVX命令を利用して、高速にGRAPE-5相当の重力相互作用計算を行う手法についての論文が投稿された。 我々のグループでも、2011年の卒業研究(鈴木裕太さん)で、OpenCLによる重力相互作用計算をテーマとして、 以下のような結果が得られている。
- AMDのGPUでは、最新のOpenCL実装であればILと同程度の性能を得ることができる
- この時、一番高速になるのはfloat4を使ったベクトル化バージョンである
- Core i7 2600Kにおいては、AMDのSDKではfloat4を使ったベクトル化バージョンが速く、IntelのSDKでは明示的なベクトル化にはあまり効果がなく、ベクトル化せずとも同等の速度
- Core i7 2600Kでの性能は最大2.1 G interactions/sec (2.1e9)
この卒業論文の結果の一部は天文学会発表のスライドで流用している。 float4を使ったベクトル化バージョン(鈴木バージョンを中里がアップデート)は、以下のようなものになる(gist)。
コードを見るとわかるように、これはI粒子4個 x J粒子4個でループアンローリングするコードに相当する。 AMDのVLIW5やVLIW4のGPUでは、この方法が一番速いと思われる。 このコードでは共有メモリは使っていない。1行がそのためのおまじないである。今はいらないかもしれない。
このカーネルで、改めてベンチマークを取ってみた。 Plummer sphereを適当なステップ数だけ積分して、一秒あたりの相互作用の演算回数を計測した。
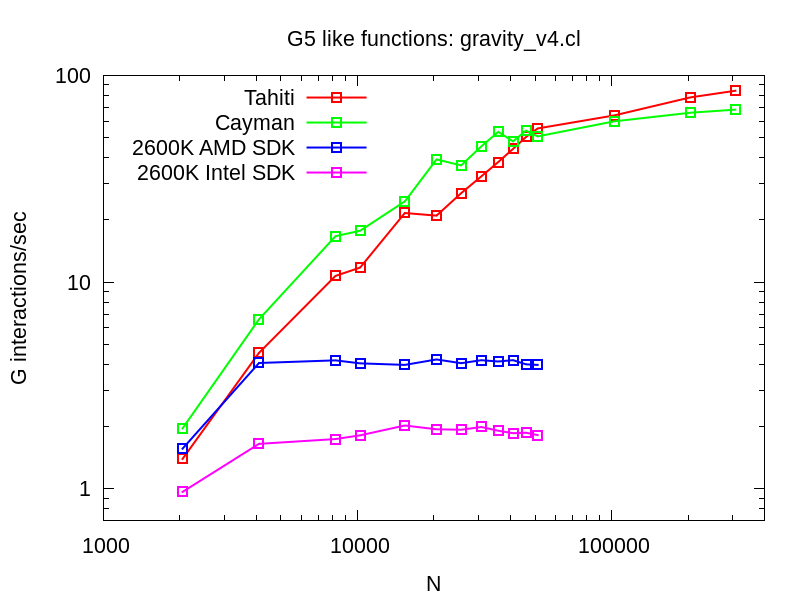
GPUのほうはまだ性能がサチってはいない。 CPUは、できるだけ谷川(2012)と同じ条件で計測してみたが、我々の環境ではHTはonになっている。 結果、AMDのSDKを使った場合約 4 Gint/secくらいになり、Intel SDKを使った場合約 2 Gint/secくらいになった。 谷川(2012)と比べるとほぼ2分の1の性能である。 上に示したような単純なコードで、inline assemnlyを使ったものと比べてこれくらいの性能がでるのなら、 案外いいともいえるし、OpenCLってやっぱり微妙だよねともいえる。
谷川(2012)との違いは、彼らのコードはI粒子 4 個 x J粒子 2 個で計算をしていて、 かつ、I粒子をOpenCLでいうところのfloat8変数にいれて、明示的にAVX命令を使うようにしていることである。 こうすると、上のOpenCLコードでの”shuffle”の部分がいらない。 実際に上のコードから生成されるx86_64のアセンブリコードを見てみると、”shuffle”の部分に結構な手間がかかっている。 AMDのVLIW5やVLIW4のGPUでは、VLIWなのでこのようなシャッフル(正確には水平方向のシフト)は、 読み出しレジスタのポートを変更するだけであり、特にオーバーヘッドがない。 しかし、SSEやAVX命令には、水平方向のシフトを効率よくおこなうための命令がない(ようだ)。
谷川(2012)と同じようなコードをOpenCLで書くことは難しくない。 ので、やってみたのが以下の結果。
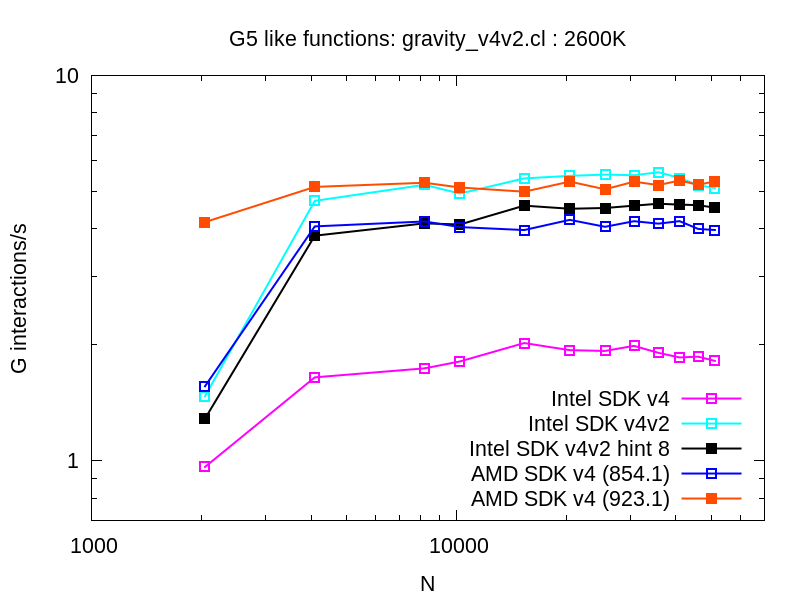
“v4v2”というのが下に貼り付けた(gist)のコードによる結果である。 AMDのSDKでは、このコードは非常に遅いので、結果を載せていない。 “hint 8”とある線は、ベクトル化のヒントを与えた場合である。詳しくは省略。
結果として、谷川(2012)と同じような実装にすると性能は大きく向上した。 具体的にはもともと最大で約 2 Gint/secだったのが、最大で約 5.6 Gint/secになった。 それでも、まだ彼らの結果(約 8 Gint/sec)には及んでいない。 これ以上は命令を並び替えるなどして、レジスタの利用を最小限とするような最適化が必要だろう。 なおIntelのSDKでは、自動ベクトル化をするため、それが悪影響を及ぼしている可能性がある。 これは生成されたアセンブリを見ればわかるはず。というのは宿題にする。 また、他のアーキテクチャのCPU (AVXをサポートしているBulldozerや、あるいはAMDのAPUやCellBE)ではどうなるかなど、 試すべきことは色々ある。これもそのうちの宿題。
最後に、谷川(2012)と決定的に違うのは、Nに対する立ち上がりのゆるさ。 ここが今の結果では致命的に遅い。本当はもっと速くてもいいはずであるが。。 でも、数時間でちょいちょいとやった割には、結構よい性能じゃないですか?
追記:AMDのSDKの最新バージョンでも試してみた。全体的に性能が上がり、立ち上がりの問題も消えている。